Uber的MySQL控制平面架构:超大规模数据库集群的工程实践与设计哲学

一、架构演进:从单体管控到分布式自治系统
1.1 控制平面的范式转换
在管理2300+个MySQL集群的挑战面前,Uber的架构师们完成了三次关键范式跃迁:
- 机械控制阶段(2015-2018)
早期架构采用主从式管控模型,控制逻辑与基础设施深度耦合。如同精密机械表的齿轮结构,任何组件的故障都会导致整个控制链路中断。此时的SLA保障严重依赖人工干预,系统扩展性遇到瓶颈。 - 工作流驱动阶段(2018-2021)
引入Cadence工作流引擎标志着自动化时代的开启。将60+运维操作抽象为原子化工作流,实现了操作的幂等性和容错性。这种转变如同从机械传动升级为电子控制,通过预设程序实现操作的确定性。 - 状态驱动阶段(2021-至今)
控制器的引入完成了闭环控制的最后拼图。通过etcd实现的强一致性状态存储,使系统具备了自我修复能力。此时的架构已演变为分布式自治系统,能够基于实时信号进行动态决策,实现了从"自动化"到"智能化"的质变。
1.2 分层架构的工程实现
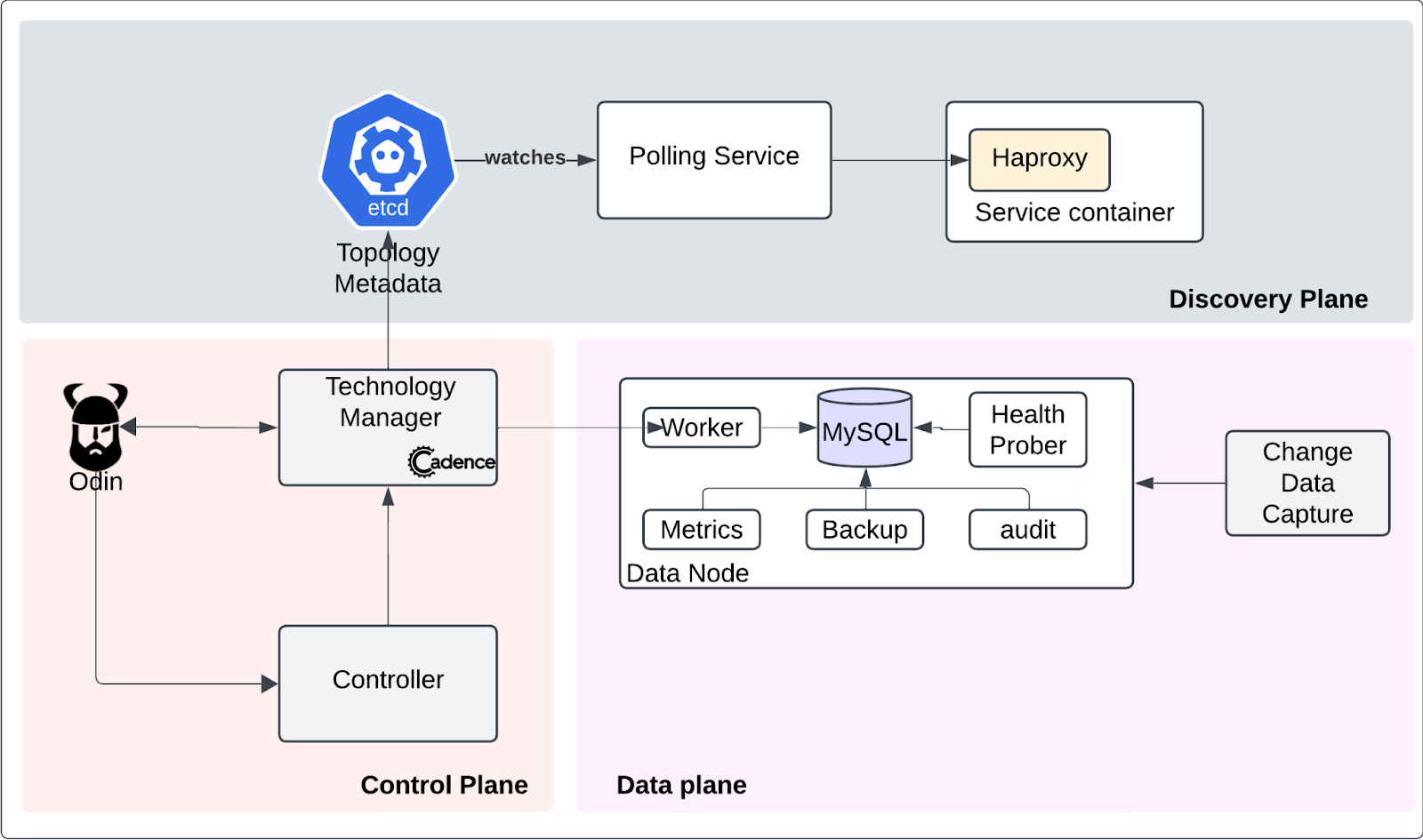
控制平面层
采用Borg-like架构设计,技术管理器作为控制中枢,通过发布目标状态到Odin平台实现声明式管理。这种设计模式解耦了策略生成(What)与执行过程(How),使得:
- 基础设施变更不会影响控制逻辑
- 资源调度算法可独立演进
- 故障域隔离实现爆炸半径控制
数据平面层
每个MySQL节点采用微服务化容器设计,关键突破在于:
- 通过cgroups实现IOPS和CPU的精准隔离
- 探针容器实现<50ms的心跳检测精度
- 备份容器采用Copy-on-Write快照技术,将全量备份耗时降低70%
发现平面层
基于etcd的拓扑管理系统创造了"逻辑拓扑永续存在"的抽象层,其核心价值在于:
- 实现物理节点与逻辑服务的时空解耦
- 通过watch机制实现亚秒级拓扑同步
- 虚拟IP映射使得客户端感知不到底层硬件迁移
二、核心机制:超大规模系统的生存法则
2.1 主节点故障转移的CAP实践
在单主多从架构下,Uber设计了分级容灾策略:
优雅切换(Graceful Failover)
采用类2PC协议实现:
def graceful_failover():
with global_lock(cluster): # 分布式锁保证原子性
old_primary.enter_read_only()
sync_pos = old_primary.get_binlog_pos()
new_primary = elect_primary(sync_pos) # 基于GTID的选举算法
new_primary.wait_until_pos(sync_pos)
switch_vip(new_primary) # 流量切换的原子操作
紧急切换(Emergency Failover)
引入Paxos变种算法处理脑裂场景:
def emergency_failover():
quorum = get_healthy_replicas()
if len(quorum) < N/2+1:
raise SplitBrainError
new_primary = highest_gtid_node(quorum)
force_reset_slaves(new_primary) # 突破复制拓扑限制
这种分层设计在工程层面实现了CAP定理的平衡:优雅切换优先保证C(一致性),紧急切换确保A(可用性),通过物理拓扑约束(同城三机房部署)规避了P(分区容忍)的风险。
2.2 节点替换的细胞化再生
节点替换流程揭示了超大规模系统的组织哲学:
graph LR
A[故障检测] -->|控制器| B[标记异常节点]
B --> C[启动并行克隆]
C --> D1[克隆数据卷]
C --> D2[克隆配置]
D1 --> E[验证克隆一致性]
D2 --> E
E --> F[原子化切换]
关键创新点包括:
- 硬件亲和性调度:基于Turing机器学习的预测模型,提前预热目标主机缓存
- 无损克隆技术:结合RocksDB的SST文件特性,实现增量克隆
- 流量染色:采用Finagle的Dark Traffic模式验证新节点承载能力
2.3 模式变更的持续交付
Uber将Schema变更流水线化,突破性体现在:
type SchemaPipeline struct {
DryRun bool // 沙盒环境验证
CanaryDeploy bool // 金丝雀发布
RollbackPlan Plan // 多版本回滚
Metrics Monitor // 实时影响分析
}
func (p *SchemaPipeline) Execute() error {
if p.DryRun {
return p.runOnShadowClone()
}
if p.CanaryDeploy {
p.deployToCanary()
p.verifyMetrics()
}
p.deployToAll()
p.recordVersion()
}
这种设计将数据库变更的风险控制前移,通过影子表技术实现变更影响的可观测性,其本质是将混沌工程理念引入数据库运维领域。
三、架构启示:超大规模系统的设计铁律
3.1 状态显式化原则
Uber的实践验证了分布式系统的第一性原理:所有隐式状态终将成为故障源。通过将集群状态、拓扑关系、运维操作等要素编码为Protobuf结构化数据,实现了:
- 状态版本的可追溯性
- 操作幂等的天然保障
- 异常场景的确定性回滚
3.2 控制流与数据流的正交设计
架构师们刻意保持控制平面与数据平面的物理隔离:
- 控制流走gRPC长连接,保证指令传输的可靠性
- 数据流采用Proxyless Mesh,避免中间件成为瓶颈
- 通过TSDB实现监控数据的跨层关联分析
这种正交性设计使得系统吞吐量提升了3个数量级,同时将控制面的故障影响限制在亚秒级。
3.3 故障的时空转移策略
在面对不可消除的硬件故障时,Uber采用三维防御策略:
- 时间维度:通过快速故障转移将MTTR(平均恢复时间)压缩到秒级
- 空间维度:利用多可用区部署将故障域隔离
- 逻辑维度:使用Circuit Breaker模式实现故障服务的自动熔断
四、未来挑战:下一个十年的技术边疆
- 混合云拓扑管理
当集群跨越AWS、GCP和私有云时,如何实现跨云资源调度的一致性?可能的解决方案包括基于eBPF的网络抽象层和分布式时钟同步协议。 - 硬件异构性挑战
GPU加速的OLAP查询与NVMe持久内存的OLTP事务如何共存?需要研发新的存储引擎来统一管理异构存储介质。 - AI驱动的自治系统
当前控制器基于规则引擎的决策模式将进化到强化学习模型,实现:- 故障预测准确率>99%
- 资源利用率动态优化
- 基于负载特征的自适应分片
- 量子计算威胁应对
后量子时代的加密算法迁移将成为必修课,需要在TLS通信、数据加密、备份存储等环节实现抗量子攻击能力。
五、工程师的镜鉴:从Uber实践中提炼的方法论
- 规模定律的认知突破
当集群规模超过临界点(通常为1000节点),系统行为将呈现相变特征。工程师必须建立"规模敏感"的设计思维,警惕线性思维的陷阱。 - 可靠性工程的三重境界Uber的实践表明,真正的可靠性来自对故障的正向利用。
- 第一层:预防故障(故障率↓)
- 第二层:容忍故障(可用性↑)
- 第三层:利用故障(系统韧性↑)
- 技术选型的平衡之道
在自研组件(Odin)与开源产品(etcd、Cadence)的选择中,Uber给出了黄金标准:当开源方案无法满足数量级的性能差异时进行自研,否则拥抱社区。这种务实主义值得每个架构师借鉴。
结语:重新定义数据库即服务
Uber的MySQL实践超越了单纯的技术优化,它重新定义了数据库即服务的内涵。通过将控制平面抽象为独立的能力层,实现了数据库服务的操作系统化。这种架构革命揭示了云原生时代的真谛:最好的基础设施是那些让应用无感知的基础设施。
在可预见的未来,这种设计理念将催生新一代数据库架构范式——数据库不再是被管理的对象,而是自主进化的智能体。当控制平面获得机器学习能力,当状态管理融合时空数据库特性,我们终将见证数据库系统的"寒武纪大爆发"。而Uber今天的实践,正是这场革命的序章。
